缘由
这几天正好帮朋友装机,弄到一张技嘉的RTX 3080 10G的显卡,闲来无事想看看N卡的CUDA”护城河“到底有多强,就拿来和蓝戟A770 16G 亚运特别版对比,测一下语言大模型和AI画图两个方面。
测试项目
这次选的是LM Studio和Stable Diffusion(秋叶大佬的绘世启动器),语言大模型采用的是deepseek的两种模型,分别是deepseek-r1-distill-llama-8b和deepseek-r1-distill-qwen-14b。Stable Diffusion的设置关闭共享显存,其他全默认。生图设置是512*512,三标签,迭代步数150steps,8张。美少女,水手服和D微笑三个标签。
LM Studio
先来看看语言大模型吧,用的是我们的国产新秀deepseek,这里用了两种参数量的模型,8b和14b。这次测试准备了三个问题,分别是:
Q1:你好
Q2:你觉得英伟达怎么样?
Q3:你了解英伟达公司的1080显卡吗?
这三个问题很简单,主要记录的数据是每秒生成token数(平均生成速度)和生成第一个token的延迟。第一个问题当然能达到很快的速度,但是多问几个问题才能看出实际上使用的平均速度。先解释一下”每秒生成token数“和”生成第一个token的延迟“两个概念吧。
每秒生成token数(下文统称为平均生成速度),就是你能感知到的文本生成的速度,文字生成的速度,这很好理解。平均生成速度是使用大模型时最直观的感受,平均生成速度只要比你的阅读速度快,那就不会感受到不舒适,就像我们说很慢之类的。我个人来说,只要高于10tokens/s就已经感觉不到不便了。平均生成速度与显卡的性能息息相关,当然还有使用的引擎。我们所说的CUDA就是nvidia独有的API(接口),因为老黄的提前布局,很多AI软件,工业软件等都依赖于CUDA,所以才会被人们戏称为是”CUDA护城河“,这确实是没有办法。所以说现在N卡卖的贵是有道理的。专业用户和游戏用户都得用他的,当然游戏用户听得多的还是DLSS,今天因为和AI没啥关系,就先不讨论了。
另外一个概念就是”生成第一个token的延迟“了。你可以理解为生成第一个字所要的时间。为什么要讨论这个概念呢?因为大模型的运作方式是这样的:根据上下文生成。生成第一个字的时候哪里有上下文?当然是用户输入的问题啦,所以说这就关系到解析用户问题的事情了。在用户发送问题时,软件会把你的问题拆分为一个一个token,再输入进去大模型进行处理。查阅资料可得,一般情况下模型中token和字数的换算比例大致如下:
1 个英文字符 ≈ 0.3 个 token。
1 个中文字符 ≈ 0.6 个 token。
所以说,大概来说,可以看成一个汉字等于1token。(我是不是要在平均生成速度里面先说的TT)当你生成完了了第一个token之后,下面所有的token生成方式就是增量式生成了,就是我们所说的结合上下文得出答案。万事开头难嘛,第一个把前期工作做好以后,其他就很简单了。所以说这就是为什么我们要讨论生成第一个token的延迟的原因了。
当你理解完上面的两个概念之后,就来看看下面的数据吧:
RTX 3080 10G
deepseek-r1-distill-llama-8b
Q1:94.07 tok/sec 0.39s to first token
Q2:45.25 tok/sec 0.11s to first token
Q3:46.70 tok/sec 0.14s to first token
deepseek-r1-distill-qwen-14b
Q1:13.34 tok/sec 0.12s to first token
Q2:10.37 tok/sec 0.27s to first token
Q3:9.51 tok/sec 1.02s to first token
A770 16G
deepseek-r1-distill-llama-8b
Q1:42.73 tok/sec 0.52s to first token
Q2:40.82 tok/sec 0.70s to first token
Q3:37.87 tok/sec 2.97s to first token
deepseek-r1-distill-qwen-14b
Q1:24.19 tok/sec 0.46s to first token
Q2:21.78 tok/sec 1.25s to first token
Q3:20.74 tok/sec 5.03s to first token
可以看出,平均下来每问一个问题,平均生成速度就会下降一些,当然之后会趋于稳定。一般来说,问了三四个问题之后速度就稳定了,比如说我日常用的A770 16G,速度就会稳定在20tokens/s左右。以8b的模型为例,我们除去第一个问题,计算一下第二,三个问题的平均生成速度,可以发现RTX 3080的速度大概在45.98tokens/s,而A770的速度大概为39.35tokens/s,生成第一个token的延迟来说,也是RTX 3080好于A770。这个差距的主要原因在于,N卡利用的是CUDA进行计算的,而A卡只能利用Vulkan进行运算。两种不同的API计算速度和效率当然有区别,结合上文可知大多数大模型对于CUDA更友好,所以利用效率和速度更不错。
夹杂私货?!(bushi)
不过N,I两家显卡跑同一个模型,回答同一个问题时也会不太一样,这确实挺奇怪的。比如说Q2:你觉得英伟达怎么样?
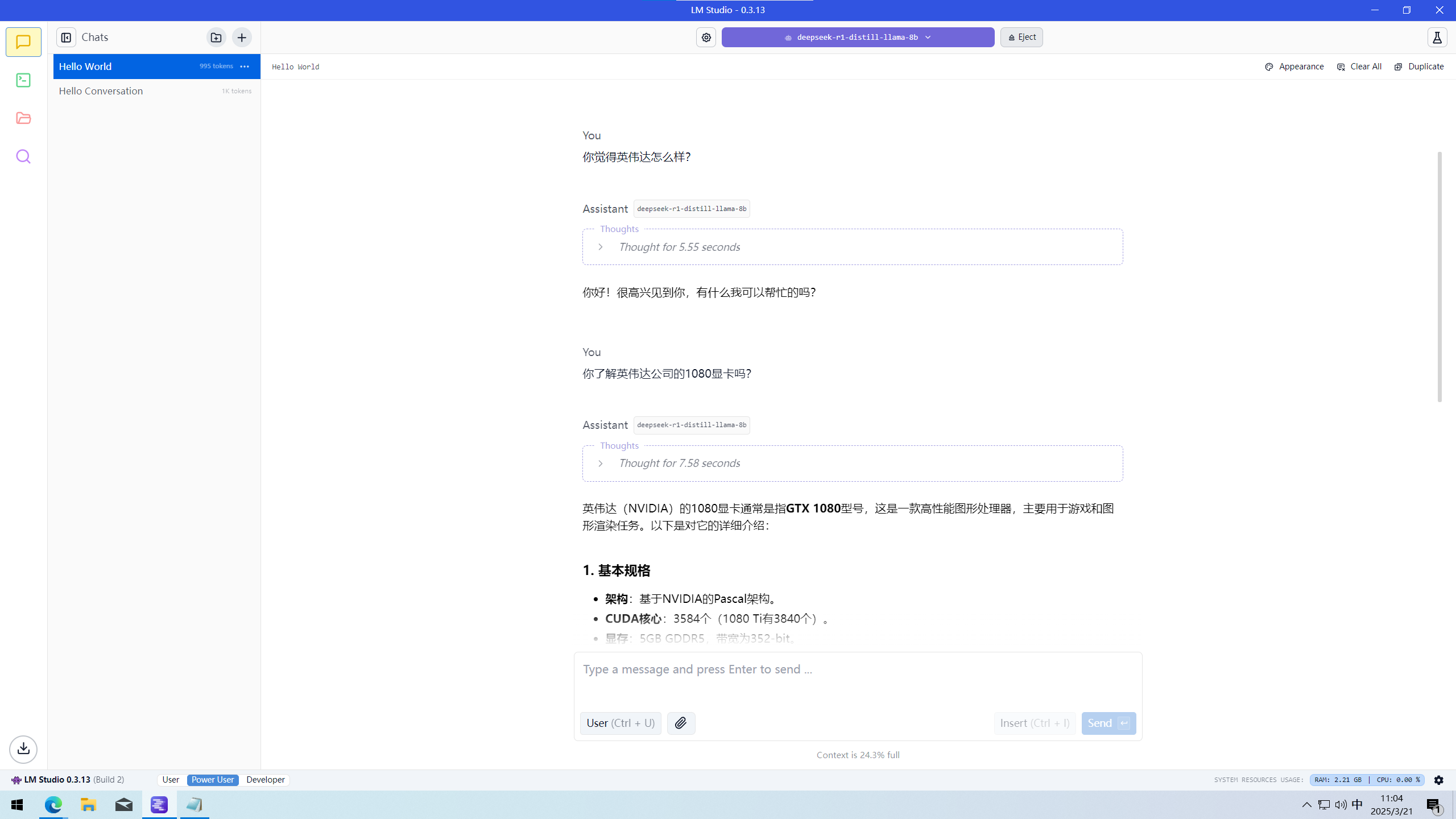
RTX 3080 10G如图
再来看看A770的表现
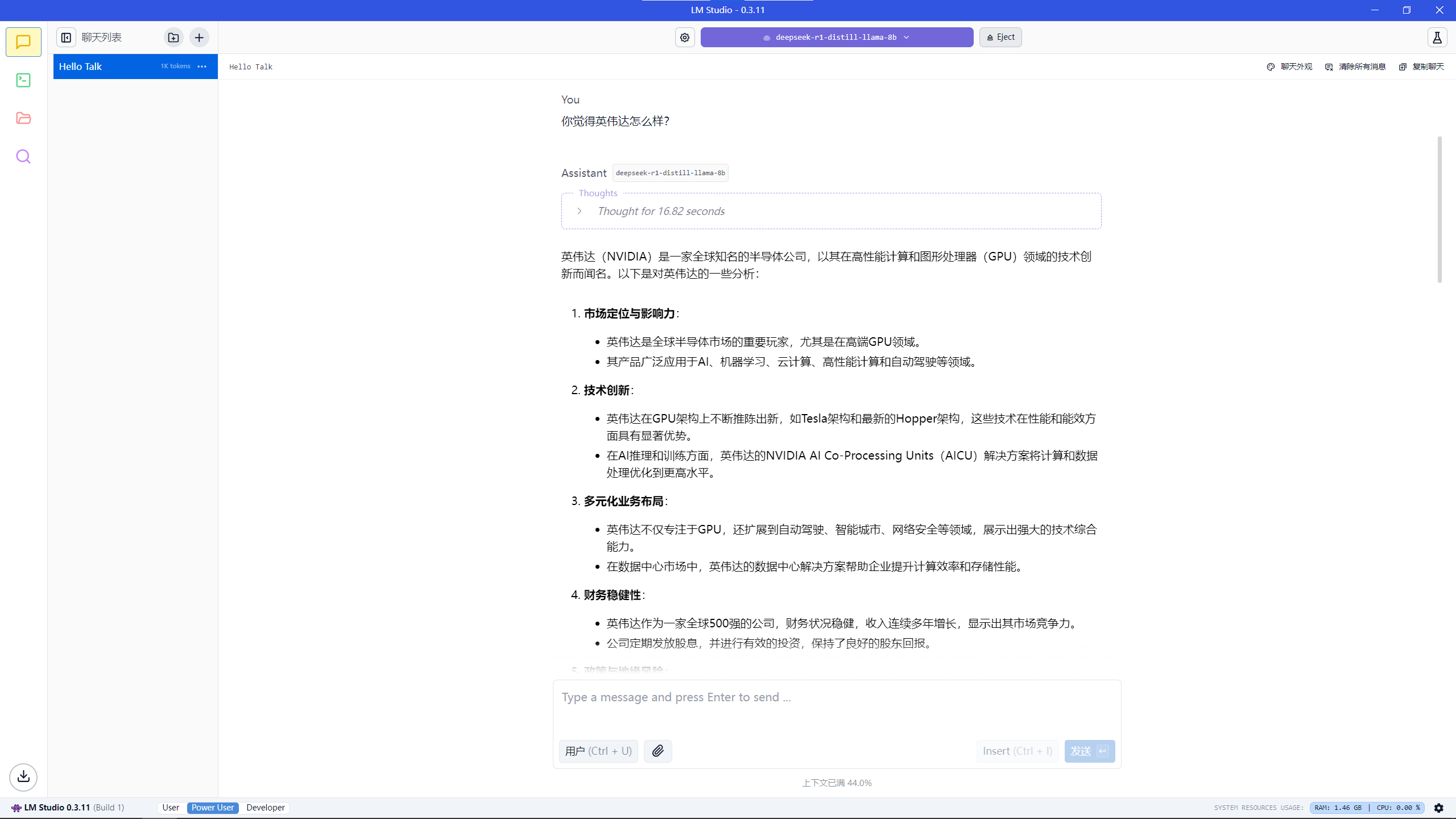
A770 16G如图
这不会是暗藏私货吧QAQ,N卡不评价自己公司?!当然我只测了一次,再测几次我也不知道会不会是这样。
不同参数大模型对比
接着我们来看两种不同参数大模型的对比。你可能会好奇:在14b模型中,为什么3080的平均生成速度比A770慢呢?CUDA不是很强吗?哈哈,这就要谈谈两种显卡的显存大小了。显存大小影响着装载大模型的大小,大模型的大小一般是由参数量决定的,也就是我们所说的8b和14b两种,”b“代表着billion,也就是千万。参数量越大的模型,就越聪明,给出的回答就更标准,一本正经地胡说八道的概率也就越低。我们所用的这两种模型其实都不是满血的,满血模型大小应该是671b,8b和14b只是从671b中精简出来的,称为蒸馏模型。因为模型是直接在显存中运行的,所以运行参数量越大的模型,就需要越大的显存。
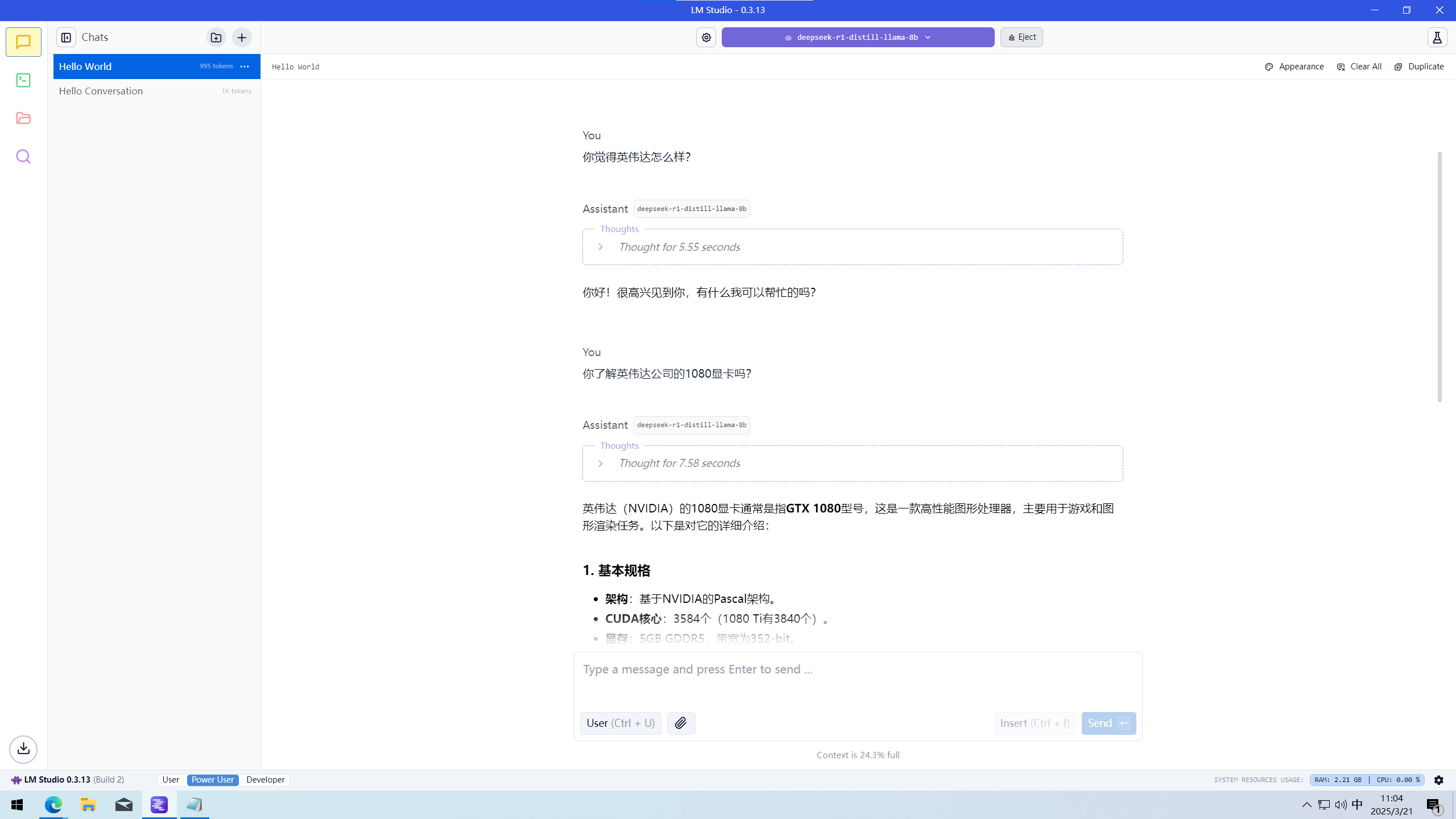
RTX 3080 10G 跑deepseek-r1-distill-llama-8b
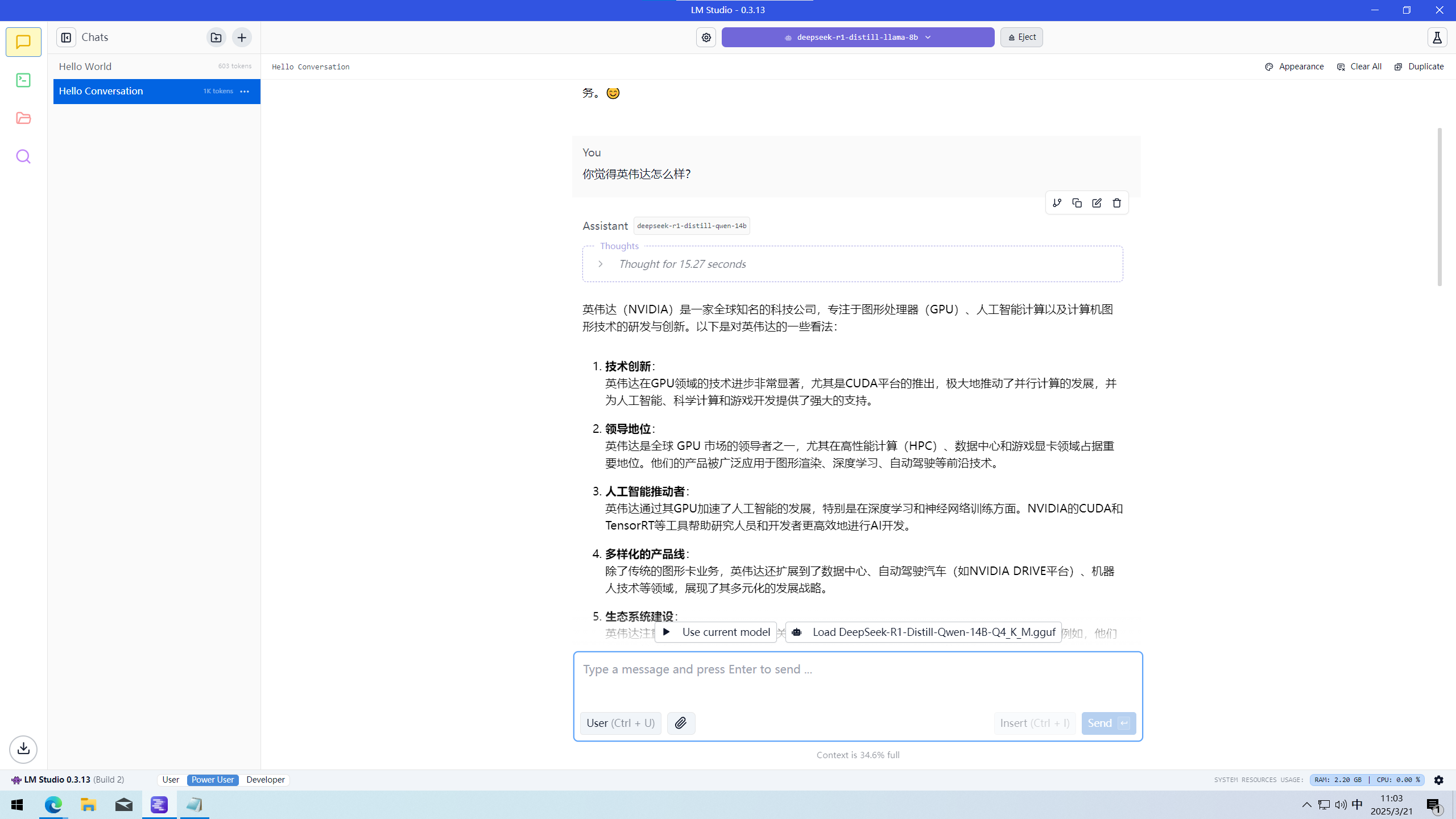
RTX 3080 10G 跑deepseek-r1-distill-qwen-14b
回归正题,RTX 3080会更慢呢?在我们这次测试的两张显卡中,RTX 3080只有10G的显存,而A770却有16G的显存。8b模型的大小是4.58G,而14b模型的大小是8.37G,由于量化方式的不同,实际还要更大一些。实测发现,RTX 3080在运行14b模型时除了吃满自己的10G显存外,还要占用4G内存。这就是我们所说的”显卡爆显存了“,爆显存会使模型的生成速度显著下降,因为显存的频率是远远高于内存的,数据交换的速度也是更快。一旦占用内存,那就会使数据交换的速度下降,你看到的平均生成速度也就会很慢了。
所以说,大显存才是跑大模型的关键,能不能跑,比跑的快不快更为重要。
用CPU+大内存跑语言大模型
你可能会问:那显存吃满了会占用内存跑,现在显卡那么贵,大显存的显卡就更贵了,我能不能单纯用内存跑呢?内存可比大显存的显卡便宜多了。
欸,你问对了,还真可以!不过速度嘛......确实感人QAQ。当你在用内存跑时,负责计算的就不是GPU了,而是CPU。CPU本身核就不多,不像显卡那样动不动就上千上万个核,所以说速度真的会很慢。比如说我的I5-12490F,6核12线程,在内存为DDR4 3200Mhz 32*2的情况下,运行deepseek 32b模型时,生成速度大概是6-7tokens/s,这速度真的很难受,如果说你不在意速度,有的是时间等的话,那当我白说。网上也有人用洋垃圾E5双路插满内存运行deepseek 671b满血模型,成本低,但速度会更慢。但能跑,起码比不能跑要好得多嘛。
顺带一提,CPU和GPU虽然都有核,但他们也是不一样的哦。详细说很复杂,简单来说,GPU能做的,CPU也能做;但CPU能做的,GPU不一定能做。你可以打个比方,假设他们都在数学考试,CPU相当于大人,解的是线性代数,GPU相当于小孩,只能解简单的加减乘除。这样就应该好理解了吧!
Stable Diffusion
接下来我们来简单看看AI画图吧,毕竟有很多绅士都喜欢用来生成二刺螈美少女的图片呢!这次我们考虑到两者的显存大小不相同,一次只生成8张,比较其速度。条件如下:
大小:512*512
内容:三个提示词 (咳咳,具体是什么自己看图)
迭代步数:150steps
张数:8张
RTX 3080 10G
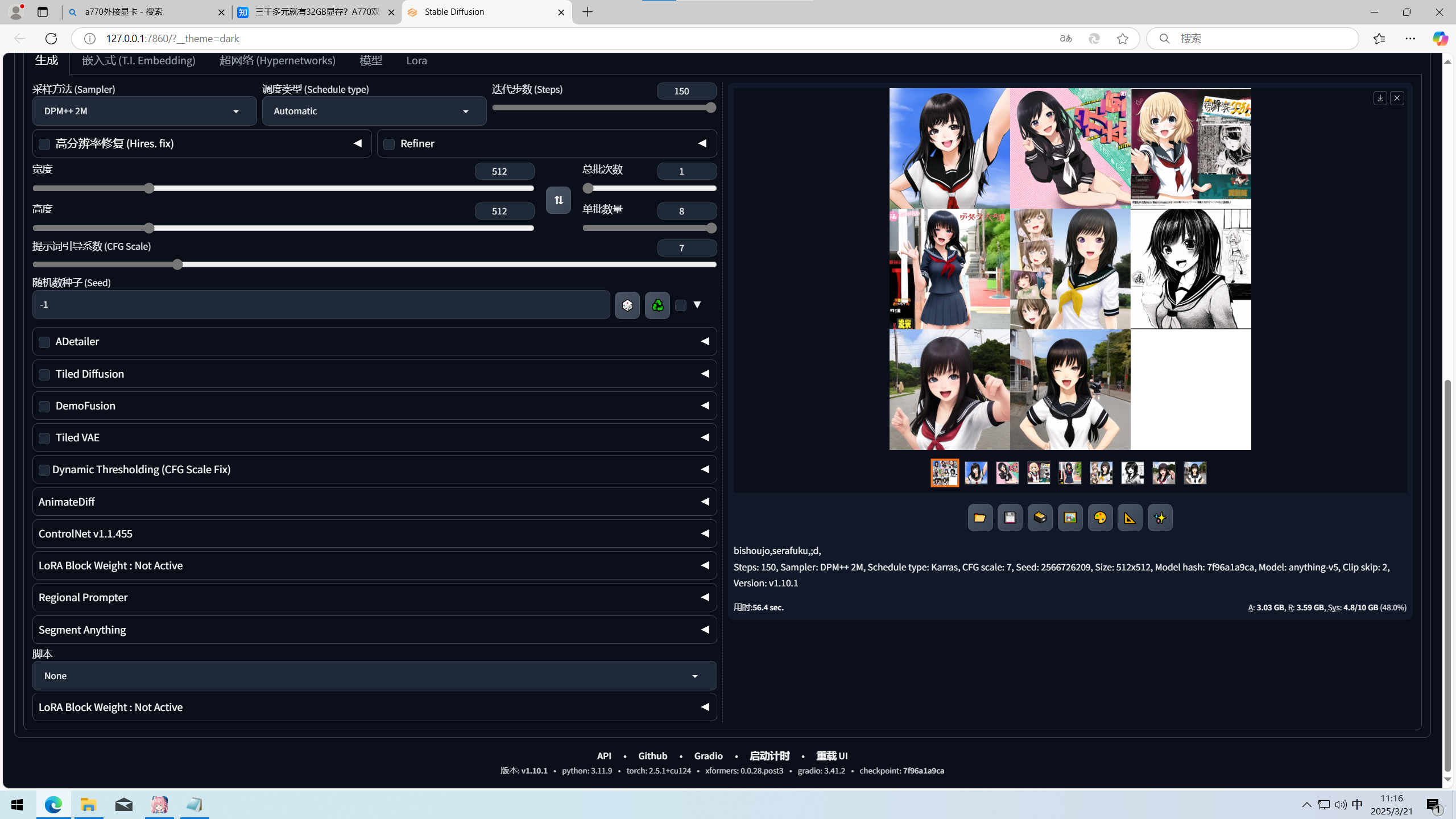
用时56.4sec
A770 16G
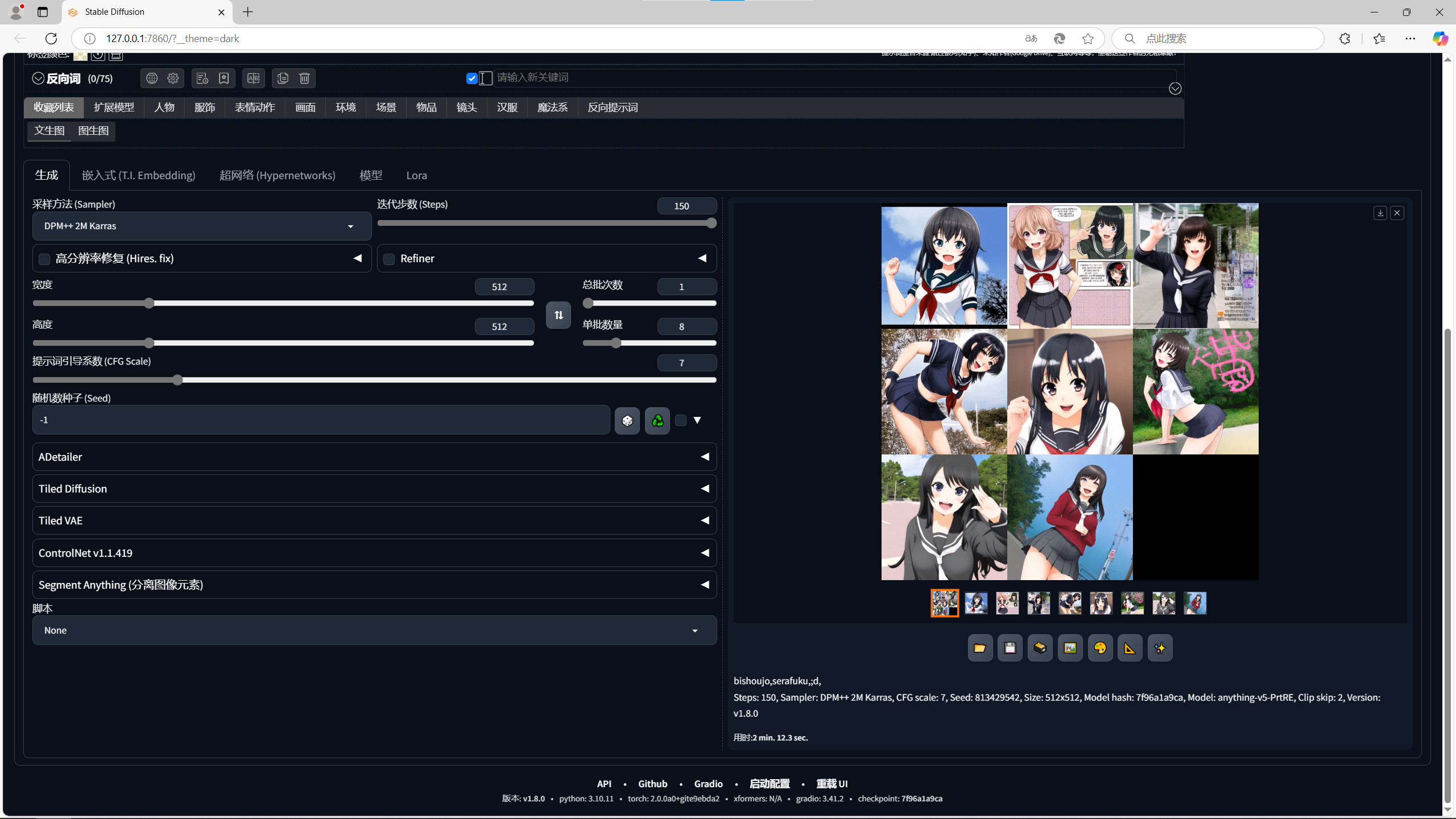
用时2 min. 12.3 sec.
事先说明,N卡用的是CUDA,而I卡用的是IPEX-LLM这个Intel官方的API,这应该不用怎么说了吧,RTX 3080比A770快了至少57.3%,这可以说CUDA真的很可怕。显存在这里已经没那么重要了,因为一般生成512*512的图都不太会爆显存,除非你一下子生成几千张当我没说。重要的是速度和质量。就算需要高分辨率的图,也是先生成低分辨率的小图,再加工扩大成为大图。
总结
N卡和I卡的AI差距其实很明显,大部分情况下都是N卡占优。但你要说谁有性价比,那肯定是I卡了。毕竟现在一张二手RTX 3080 10G才2700左右,而两张二手A770 16G的显卡小黄鱼差不多才2800元,如果是只跑语言大模型的话,那大显存肯定是比速度更重要的,还是那句话:要先能跑才有谈速度的资格。在ubuntu环境下A770还可以做到互联,组成32G的大显存。在N卡中想要有这么大的显存,那也得上5090了,价格差了不知道多少倍,而且老黄还在消费级显卡中砍掉了NV Link,所以说啊,F**k you NVIDIA!!!
总结一句话:
跑大语言模型大显存为重,跑AI画图速度快为重!