前言
现在的显卡价格真的是贵的离谱,1080P通吃的甜品卡比如说4060和6750GRE的价格都在2000左右,高端一些的4070什么的小黄鱼上面都要3500+,更别说刚出的50系显卡了,5070ti溢价都要到7200+了。我本来想着攒钱等50系出了买一张5080的,但现在这个溢价只能说让人望而却步......
那么,我们垃圾佬会捡怎么样的显卡呢?RX 580吗?不不不,这货这几年涨价涨的太厉害了,两百多的现在到了三四百块,而且都是很多翻新货,能用一个月就不亏,两个月就是赚。这次主要是花了一次乐子钱买了两张卡,P106-100和P104-100。这两张卡你可能没有听过,但其实他们都是10系的GTX1060 6G和GTX1070 8G阉割了视频输出单元而来的,具体参数我们后面再聊吧。
简介
P106-100的前身是1060 6G,具体来说阉割了PCI-E带宽,从pcie3.0 x16变成了pcie1.1 ×16,还有视频编解码单元,简单来说就是不能输出图像,其余都与1060一致。P104-100也一样,无视频编解码功能,pcie带宽是1.1×4。
为什么这种没有视频输出功能的显卡会出现呢?这是因为几年前的“挖矿潮”了,因为挖矿不用输出图像,只需要处理数据就行了,所以说当时的N卡专门推出了为“挖矿”而生的显卡,也就是我们所说的P106这种P前缀的,还有之后的30HX,40HX之类的卡,再后来矿难之后就再也没有推出过新矿卡了。
打个比方,现在1060 6G也要五六百块,所以说P106这种矿卡就显得非常香了。如果是跑AI的话(包括大模型和Stable Diffusion),那直接找个官方驱动打上就行了,比如说驱动总裁和鲁大师那些软件,非常简单易懂。
打游戏安装魔改驱动
如果打游戏的话,他也有上手门槛的,比如说你的电脑要有核显,或者是另一张负责显示的显卡来输出图像。而且要去网上下载民间大佬的魔改驱动安装。具体步骤如下:
准备东西:DDU(显卡驱动卸载软件),矿卡,魔改驱动,GPU-Z
①进“安全模式”中打开DDU,把N卡驱动卸载掉,卸载后关机。
②把你的网线拔了,如果用WiFi的在安全模式中把WiFi禁用了。
③把显卡装上,供电线也插上。
④开机,进入的肯定是正常使用的Windows。之后安装魔改驱动,按安装步骤一步一步来。
⑤在安装完之后打开GPU-Z,看看你的矿卡有没有被正常识别到。如果识别到了,那就是没问题了。如果失败,那就得从头再装一次,多次失败的话就要考虑是不是显卡出问题了。
好了,闲话少说,我们来进实测。
3Dmark Time Spy跑分
先来看看基准跑分吧:
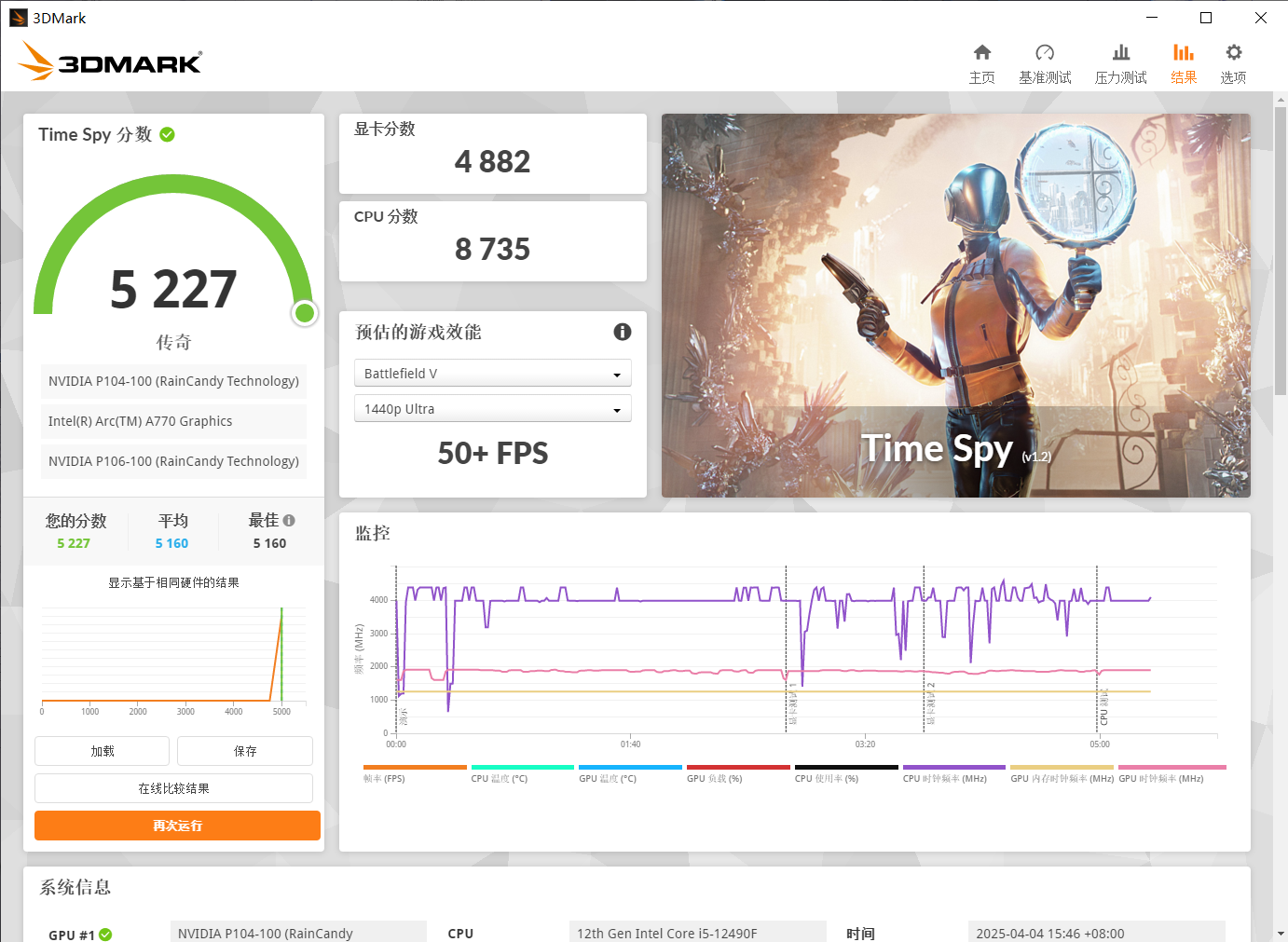
P104-100
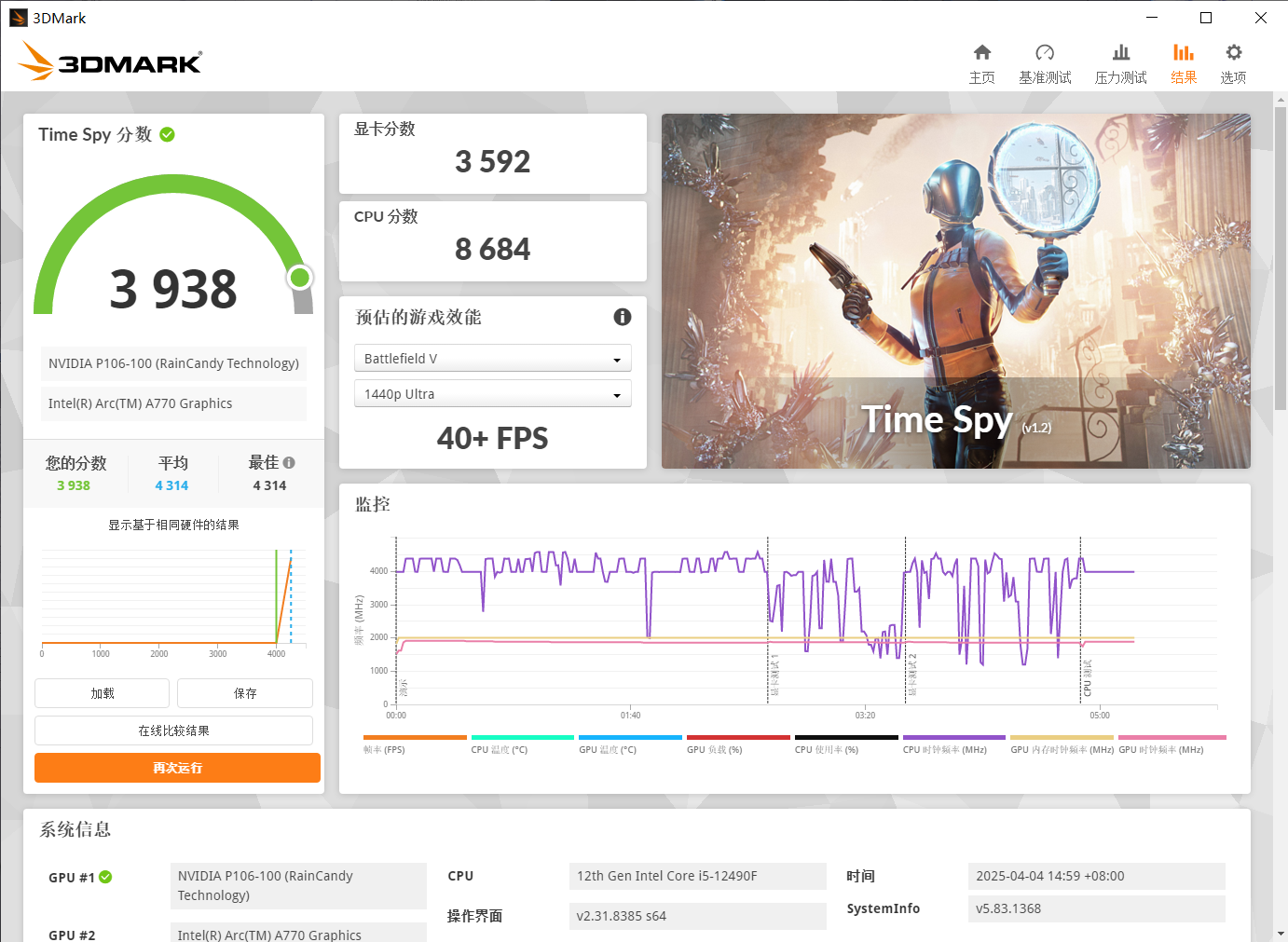
P106-100
虽然P104-100的带宽小,但是这也掩盖不了它的核心是1070阉割版,比起P106-100的1060阉割版来说,还是强很多的。顺带一提,因为主板原因,P106-100跑的pcie通道是4.0×1,虽然只有16GB/s,但是已经可以跑满了,不需要它所说的1.1×16。
AI性能
在AI方面我们用的是Ollama和Stable Diffusion。Ollama用的语言大模型是deepseek-r1-distill-llama-8b,为什么不用LMS呢?欸,因为LMS识别不到矿卡的CUDA,所以说只能换用Ollama了。SD是老设置:三标签 512*512 150steps 8张 默认设置,关闭共享显存。
Ollama的三个问题:
Q1:你好
Q2:你觉得英伟达怎么样?
Q3:你了解英伟达公司的1080显卡吗?
Ollama
首先我们来看看两张卡跑语言大模型的表现:
P106-100
Q1:prompt_eval_duration 111ms
tokens_per_second 22.48
Q2:prompt_eval_duration 177ms
tokens_per_second 20.15
Q3:prompt_eval_duration 1.23s
tokens_per_second 17.87
P104-100
Q1:prompt_eval_duration 90ms
tokens_per_second 32.14
Q2:prompt_eval_duration 125ms
tokens_per_second 28.96
Q3:prompt_eval_duration 1.19s
tokens_per_second 25.86
第一行的数据是生成第一个token的延迟,只不过在Ollama中的名称不一样。第二行的数据就是我们熟知的每秒生成token数了,这个数据是简化过的,原始数据会在后面展示出来,顺便还有返回值的注解,感兴趣的可以看看。
不难发现,无论是速度还是延迟,都是P104-100更胜一筹。看来更小带宽并没有给他太大的影响,反而是更强的核心推理速度更快。速度平均下来,P104-100比P106-100快了大约43.7%,而延迟平均也要低7.5%。更别说P104-100在Q3时的速度都超过了P106-100在Q1的速度了......所以说核心性能的强弱才是跑大模型快慢的决定性因素。
Ollama返回值注解
total_duration:生成响应所花费的总时间。
load_duration:以纳秒为单位加载模型所花费的时间。
prompt_eval_count:提示文本中的标记(tokens)数量。
prompt_eval_duration:以纳秒为单位评估提示文本所花费的时间。
eval_count:生成响应中的标记数量。
eval_duration:以纳秒为单位生成响应所花费的时间。
context:用于此响应中的对话编码,可以在下一个请求中发送,以保持对话记忆。
response:如果响应是以流的形式返回的,则为空;如果不是以流的形式返回,则包含完整的响应。
tokens_per_second:标记数每秒
注:要计算生成响应的速度,以标记数每秒(tokens per second,token/s)为单位,可以将 eval_count / eval_duration 进行计算。
原始数据
P106-100
Q1:total_duration 12.74s
load_duration 11.60s
prompt_eval_count 6
prompt_eval_duration 111ms
eval_count 23
eval_duration 1.02s
tokens_per_second 22.48
Q2:total_duration 35.38s
load_duration 13ms
prompt_eval_count 37
prompt_eval_duration 177ms
eval_count 709
eval_duration 35.18s
tokens_per_second 20.15
Q3:total_duration 81.30s
load_duration 14ms
prompt_eval_count 442
prompt_eval_duration 1.23s
eval_count 1430
eval_duration 80.04s
tokens_per_second 17.87
P104-100
Q1:total_duration 820ms
load_duration 14ms
prompt_eval_count 6
prompt_eval_duration 90ms
eval_count 23
eval_duration 716ms
tokens_per_second 32.14
Q2:total_duration 25.18s
load_duration 20ms
prompt_eval_count 37
prompt_eval_duration 125ms
eval_count 725
eval_duration 25.04s
tokens_per_second 28.96
Q3:total_duration 47.82s
load_duration 14ms
prompt_eval_count 548
prompt_eval_duration 1.19s
eval_count 1205
eval_duration 46.61s
tokens_per_second 25.86
Stable Diffusion
来看看AI画图吧:
P106-100
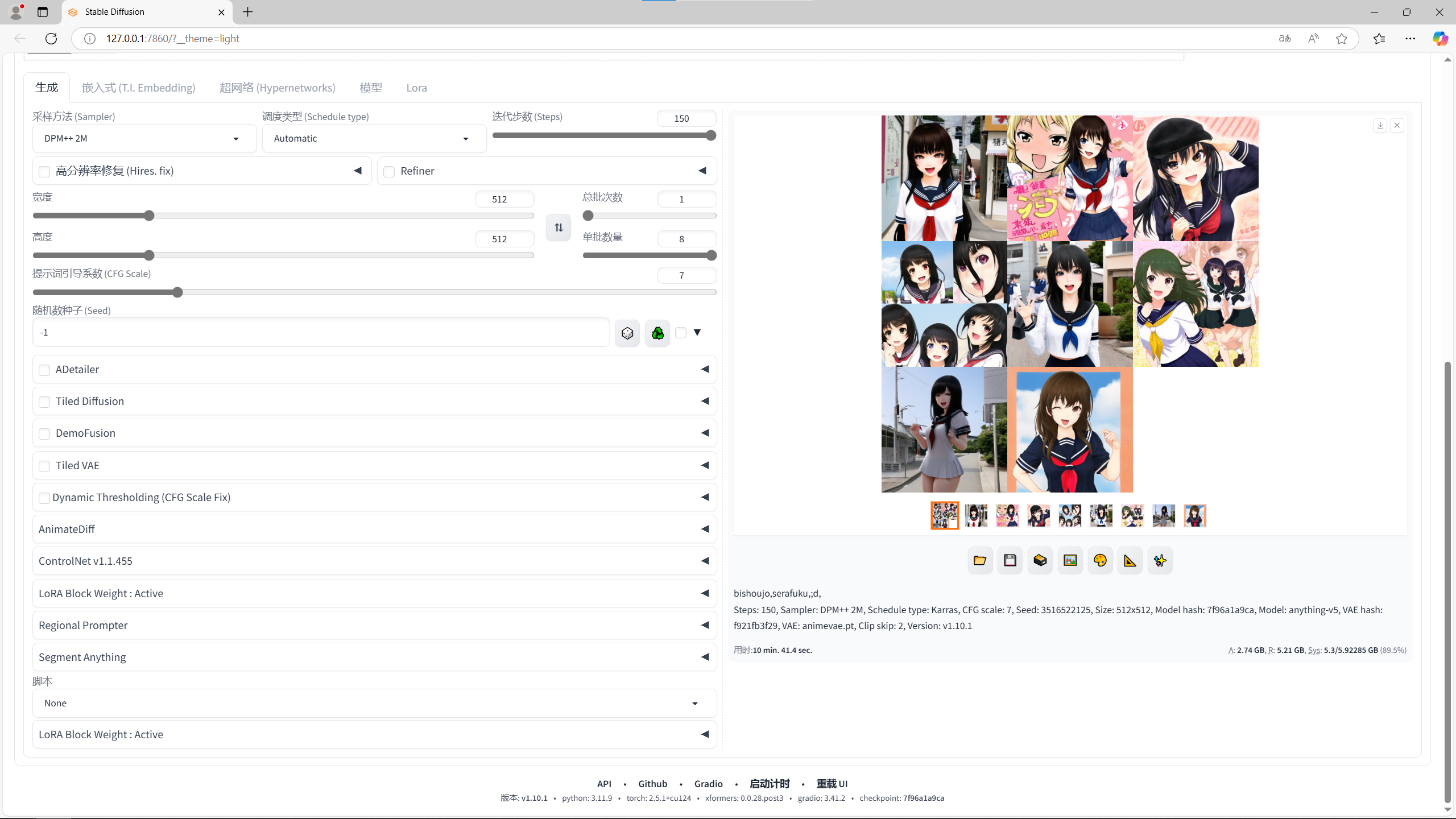
512*512 三标签 迭代步数150steps 八张 用时:10 min. 41.4 sec.
P104-100
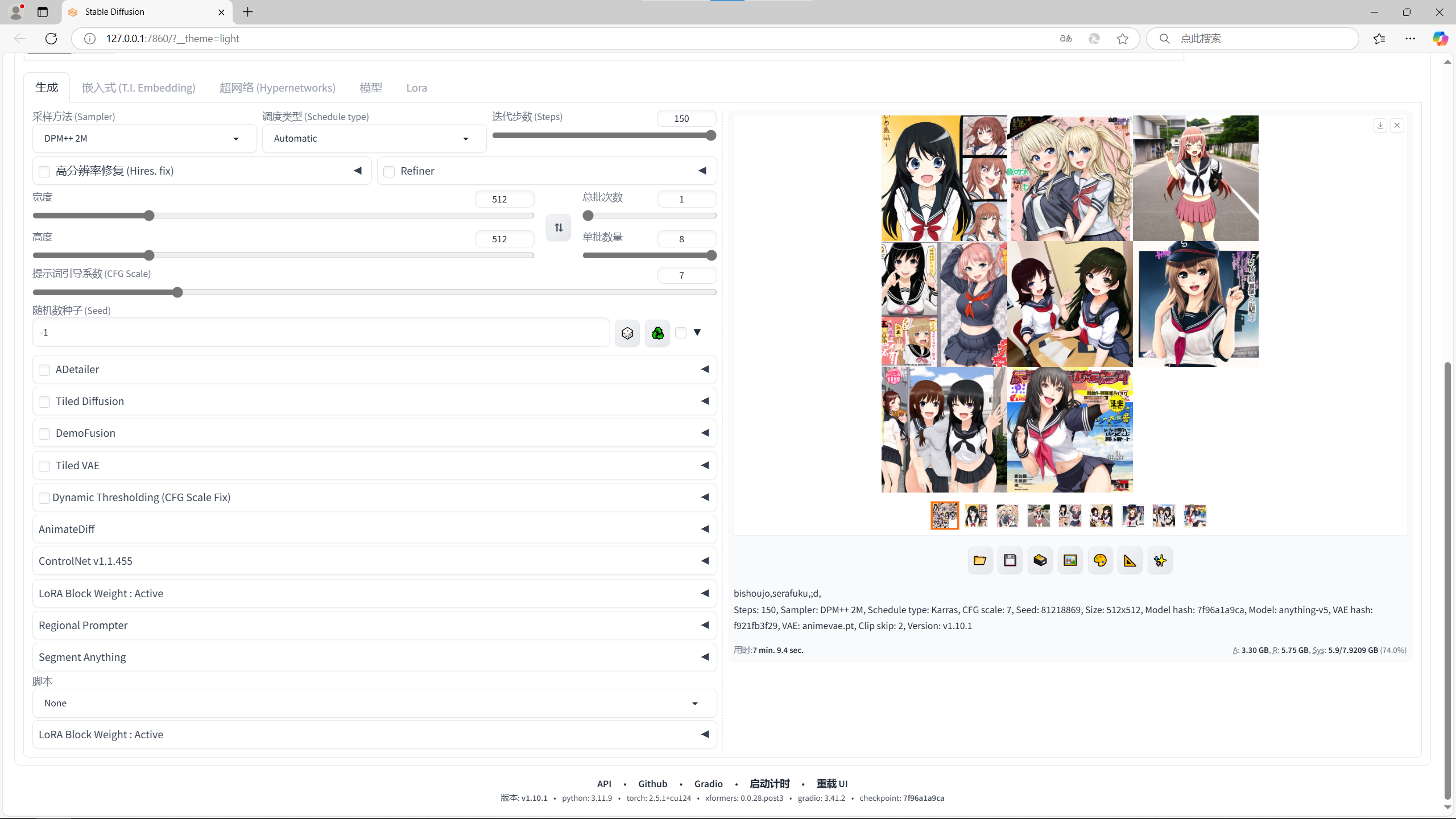
512*512 三标签 迭代步数150steps 八张 用时:7 min. 9.4 sec.
可以看出,P104-100的出图速度比P106-100快大约33%。主要原因是P104-100的核心计算能力强,带宽的影响反而没有那么重要了。所以说如果想接触一下AI画图,搞一两张P104-100还是很香的,一个乐子钱就可以玩这些,何乐而不为呢?
游戏性能
因为带宽的影响,P106的带宽高于P104,所以说P104虽然用的是1070的核心,但是带宽限制了他的发挥,导致游戏性能比P106差,这是直面参数上可以看出的,具体的表现也是和我们所预测的一致。
这次测三款游戏,分别是幻兽帕鲁,史莱姆牧场2,史莱姆牧场。三款游戏分别在2K画质下,以最低画质和最高画质测,一共测两次。
看看史莱姆牧场的表现把,差不多七年前的老游戏了,在性能这方面肯定都是足够的,N卡的话优化肯定也不会差。
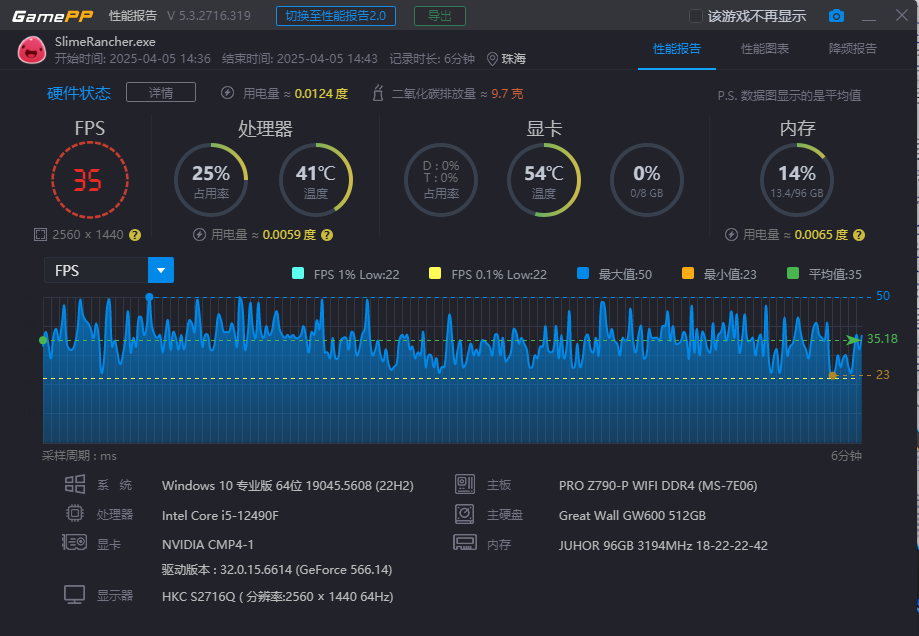
P104-100史莱姆牧场最低预设
意外
由于测的时候P106-100挂了TT,所以后面的游戏测试什么的不能测下去了,而且P104-100的调用也有些问题,所以这期只能到这里了。
总结
总的来说,在AI性能方面,P106-100还是逊于P104-100的。无论是速度,还是显存大小都要差一点。毕竟核心规模就摆在那里,一个是1060的核心,另外一个是1070的核心。但是如果是跑游戏的话,带宽影响还是比较明显的,×16和×4的差距并不是一点半点。当然我并没有暗示某款最新的显卡,用的还是×8的带宽,演都不带演了。