
前言
前几天玩腻了语言大模型和AI画图(其实也没有精通TT),就在网上冲浪找找有什么AI玩法,发现了一个神奇的东西:AI声音克隆。其实就是B站那些鬼畜视频的配音,瑞克五代的歌也是。看到了就想试试看,所以说就来玩玩吧。现在的这个模型只能读文字,还不能直接用来唱歌,像初音未来那些虚拟歌姬得更成熟的技术。
参考信息
参考文档:白菜工厂1145号员工
https://www.yuque.com/baicaigongchang1145haoyuangong/ib3g1e
准备工作
1.一张显存大于8G的N卡!!!
2.有能看懂英文的能力!(对于看命令行报错有帮助)
3.Patience is the key in life!
步骤
总的大步骤有两步,分别是获取训练数据和模型训练,小步骤还挺多的,可以按照文档自己试一试。
Step1 获取训练数据
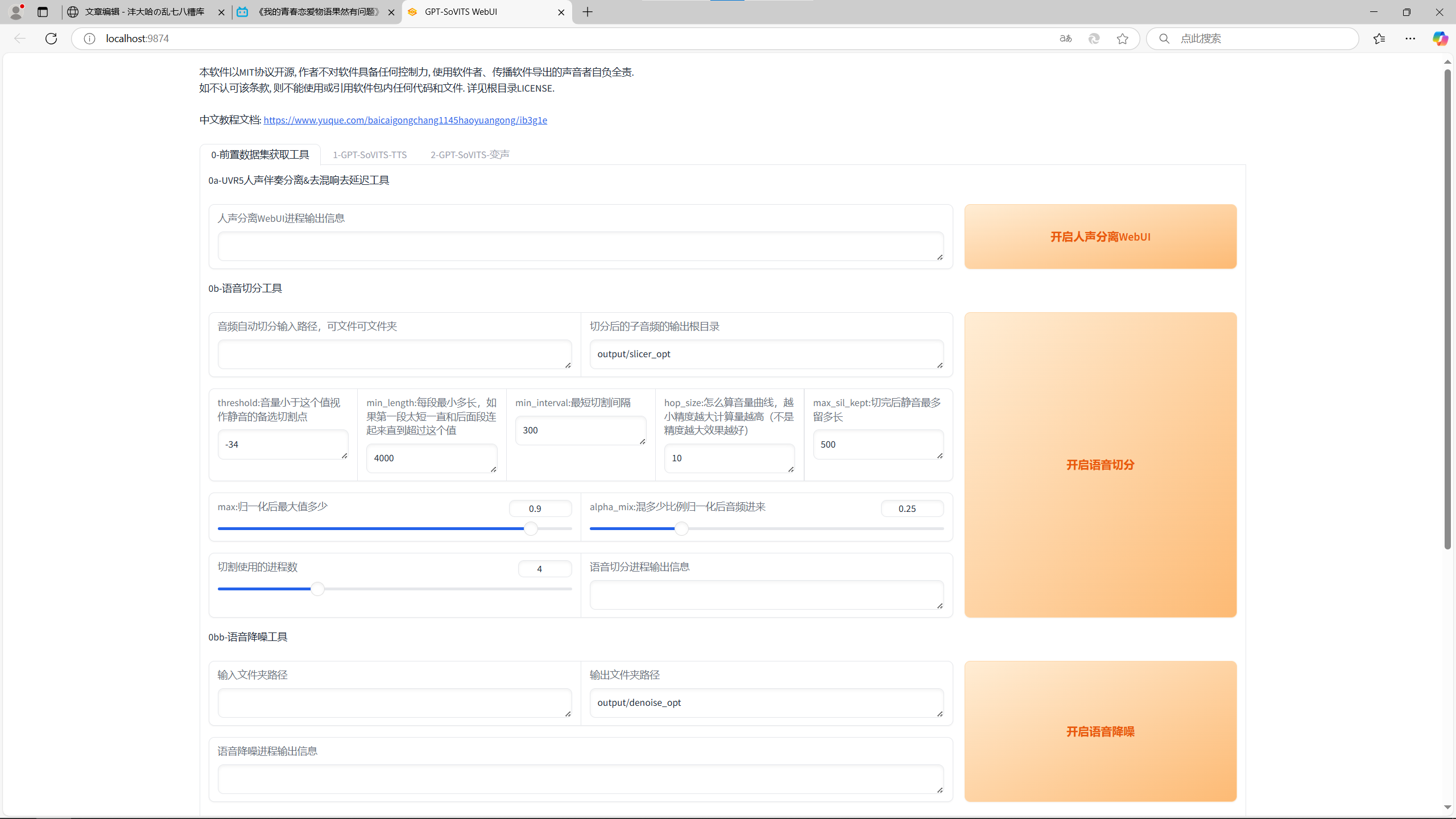
Step1的界面
Step1.1 人声分离webUI

Step1.1.1 第一次处理
打开人声分离webUI,会弹出新的界面。进去之后把导出文件格式从mp3改为wav,第一次的模型选择HP2_all_vocals,在下方导入一首音乐或者你要处理的声音素材,点击转换。
当下方输出success之后,就代表着第一次模型分离完成。第一次输出的声音在程序文件夹output里面的uvr5_opt文件夹里。在里面可以看到两个文件,分别是前缀为vocal和instrument的,你只需要保留vocal的就可以了,把instrument删除掉。你也可以试听一下处理的效果,看看怎么样。

Step1.1.1完成
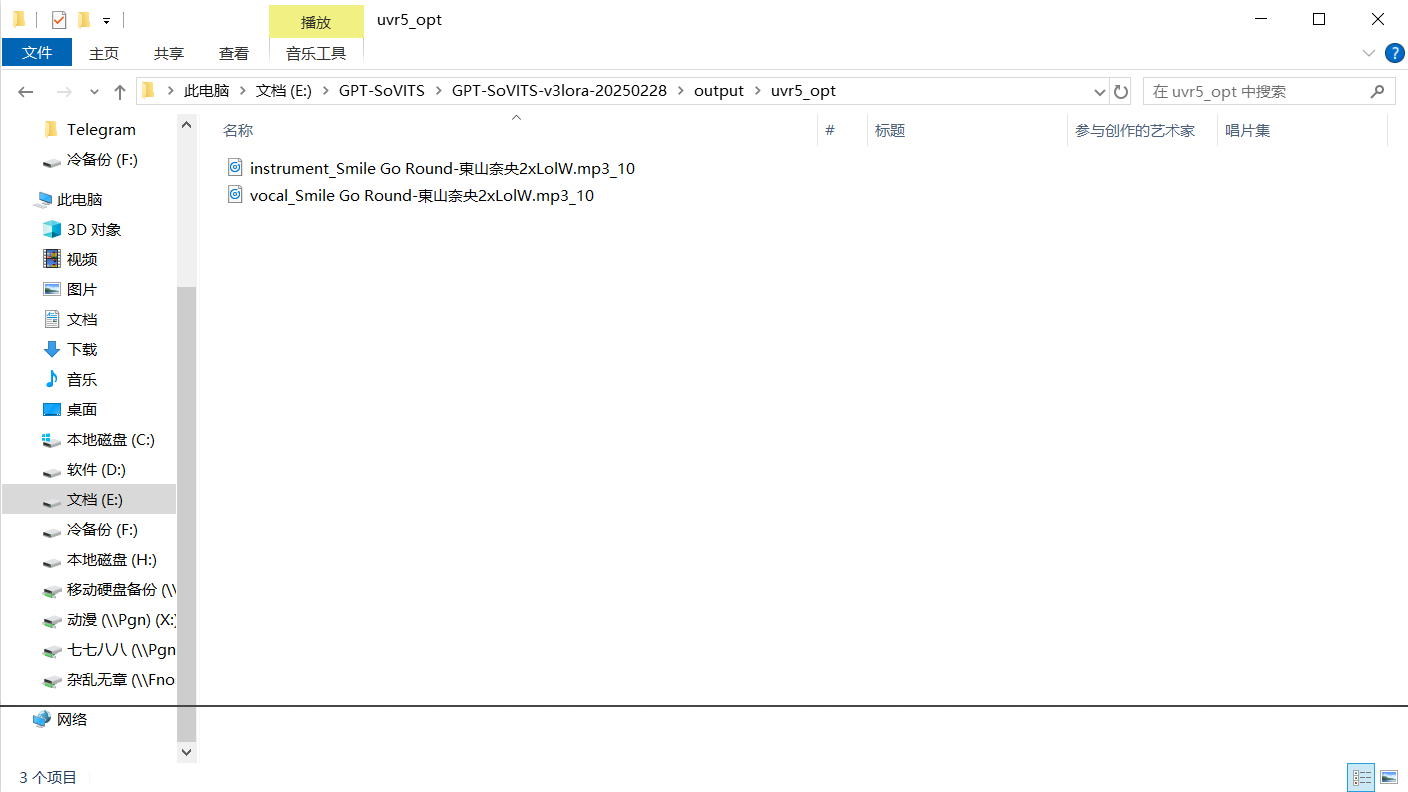
Step1.1.1结果
Step1.1.2 第二次处理
接着进行第二次模型的分离,回到浏览器的界面,删除原来的音频文件,把第一次处理好的音频放进去,模型选onnx_dereverb_By_FoxJoy,点击转换,之后会进行第二次模型的分离。第二次模型分离要的时间比较久,得耐心等候。待success再次出现后,返回uvr5_opt文件夹,看得到有一个后缀是-_main_vocal的,保留它,删掉其他的文件。
Step1.1.3 第三次处理
之后进行第三次模型分离,回到浏览器的界面,删除原来的音频文件,把第二次处理好的音频放进去,模型选择VR-DeEchoAggressive,之后点击转换。出现success之后,回到uvr5_opt文件夹,你会发现最终的结果:前面有两个vocal的文件,保留它,删除其他的。
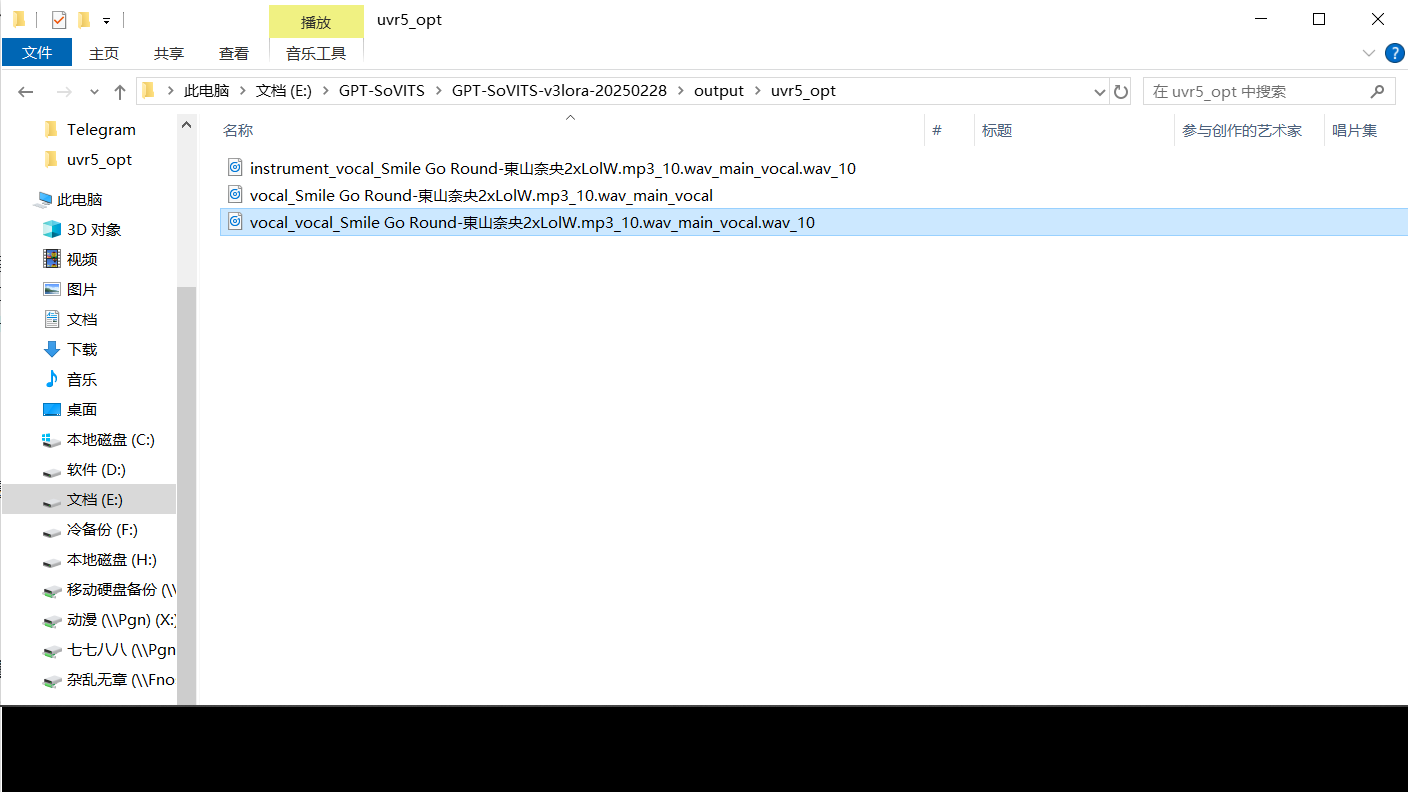
Step1.1.3结果
这三次模型分离完成,得到最终文件后,就可以关闭人声分离webUI的界面了,回到主页面,点击关闭人声分离webUI。至此,我们Step1.1就完成了!
Step1.2 语音切分
得到纯洁的人声之后,下一步就是切割语音了。把原来的一串语音按每一句切分为很多单独的音频,方便系统处理(不然你显卡没这么多显存一下子处理,得分批来)。
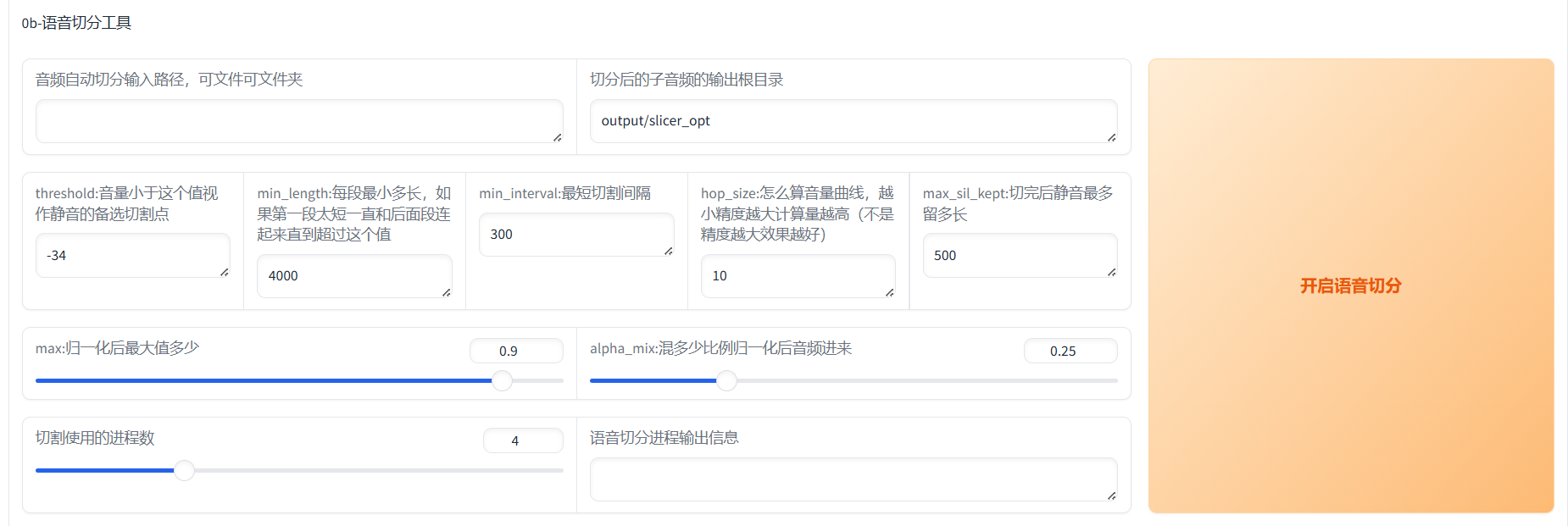
Step1.2语音切分
在音频自动切分输入路径,可文件可文件夹下面的白框中,要输入你刚刚第一步完成之后导出的音频所在文件夹。你就回到uvr5_opt文件夹,点上面有很多大于号的那一行,就能得到我们要的路径了。复制粘贴到白框中,系统会自动识别。
音频自动切分输入路径,可文件可文件夹
Step1.2文件位置
复制粘贴完路径之后,点击开始语音切分,看到语音切分进程输出信息显示已完成时,Step1.2就完成了。
注:这个输出信息就是用来看状态的,在之后的步骤中如果没有需要额外打开页面的,都会有这个信息栏,可以查看。
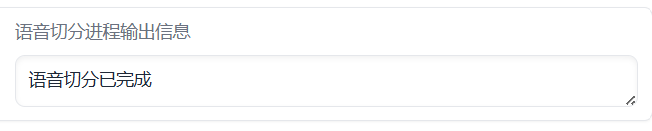
Step1.2完成标识
Step1.3 语音降噪(可选)
第三步的话是可选可不选的,就是语音降噪工具。说实话,这东西其实挺毁音质的,最好不要用。如果你真要用的话,就直接点击语音降噪,完成之后,进行第四步时把第四步的输入文件夹output\slicer_opt改成第三步的输出文件夹output/denoise_opt就可以了。
Step1.3的文件夹路径
Step1.4 语音识别
第四步就是语音识别了。这个步骤就是把你的音频说的东西识别出来变成文字,语音语调这些东西,之后方便我们训练模型。
在这里其实你只需要改变ASR 模型,这个说白了就是识别的语言,你刚刚导进去的是中文那就选达摩ASR(阿里的语言识别模型,很准确),其他的语言就选择Faster Whisper (多语种),英语日语韩语什么的都行,准确率比较高,其他可以默认。识别完毕之后直接进行第五步。
Step1.5 音频标注
第五步是音频标注,就是让你去检查机器听出来的文字对不对。打开音频标注webUI,之后可以看到一句文字之后对应一段音频,你可以花时间去听,错了就在旁边改。反正我挺懒的,相信机器的能力,就直接跳过了。
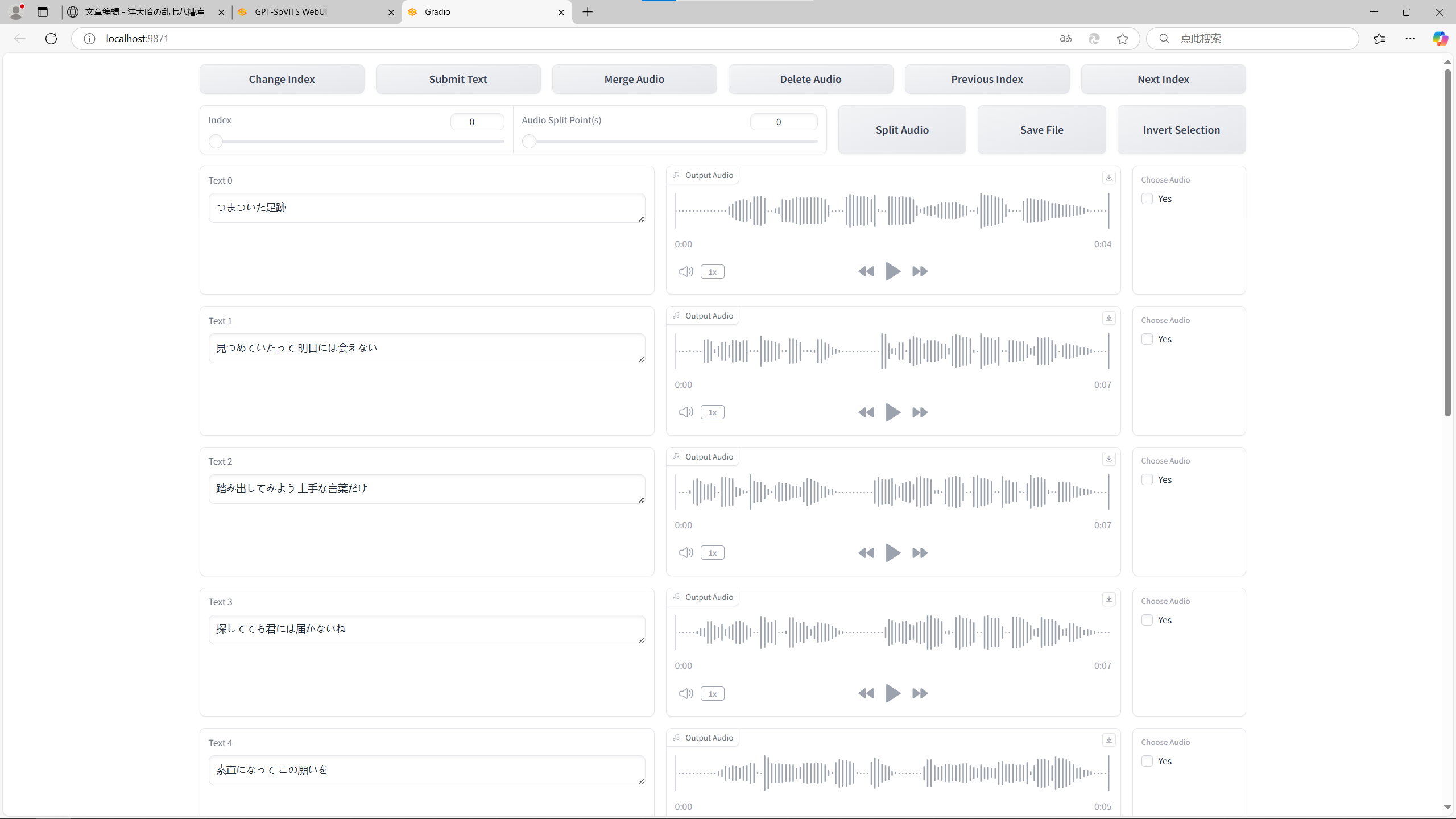
音频识别webUI
在完成以上五步之后,Step1就完成了。接下来就是把Step1处理过的数据训练成模型了。
Step2 模型训练
这一步就是一些训练集和模型微调什么的,比较复杂,但是操作简单。
Step2.1 训练集
在Step2.1中,直接点一键三连就可以了,速度很快。
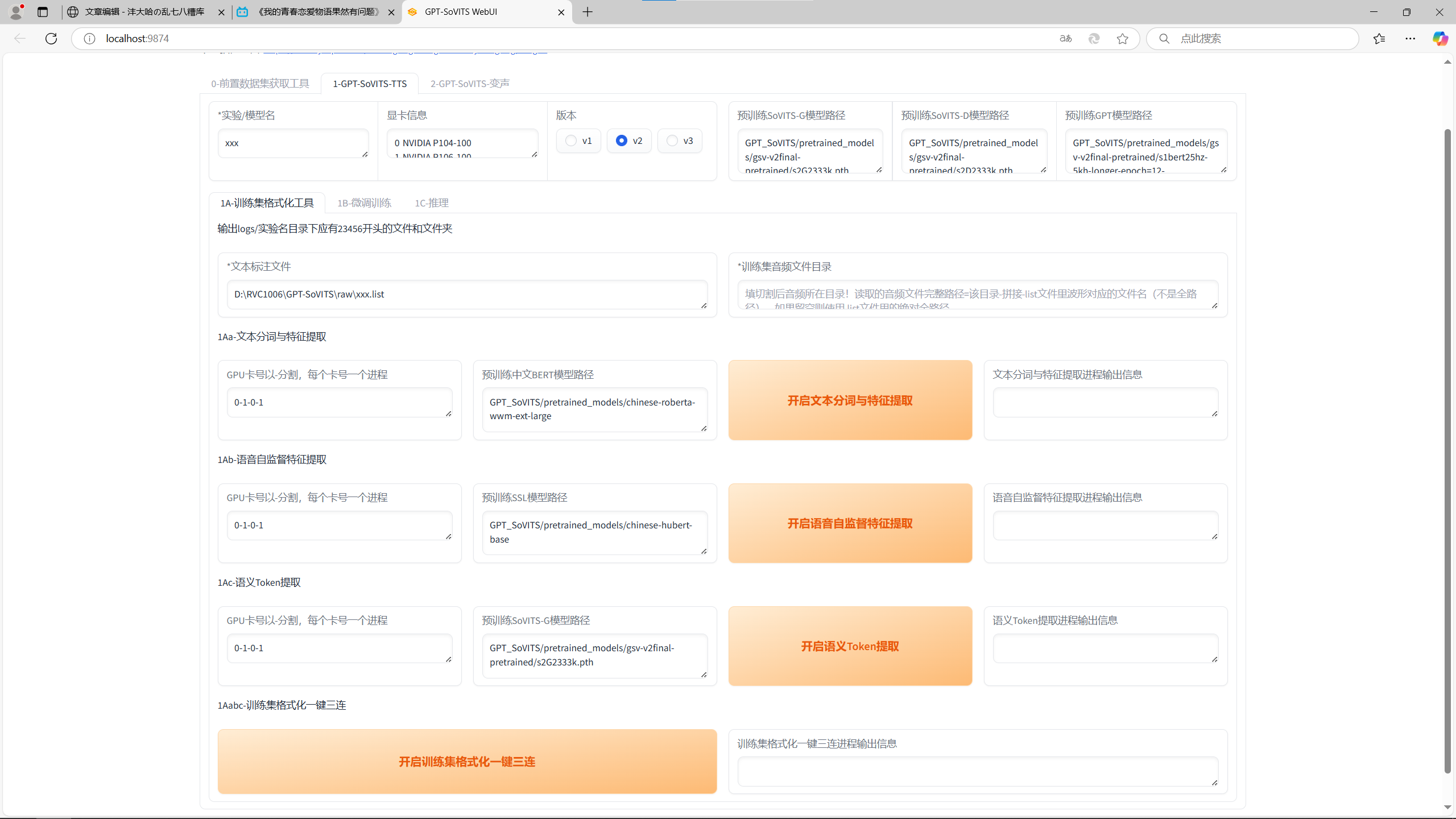
Step2.1

一键三连成功
Step2.2 模型训练
第二步就是模型训练了,在第一个训练中按照默认选项点就可以了,第二步GPT训练要特别注意了:每张显卡的batch_size这个东西按默认的话8G显存的N卡是受不了的,建议直接调到最低,也就是1就行。关于旁边的DPO训练的话,这个可以显著减轻吞字现象的,但是训练量会显著增加,没个16G显存你是根本玩不了的。
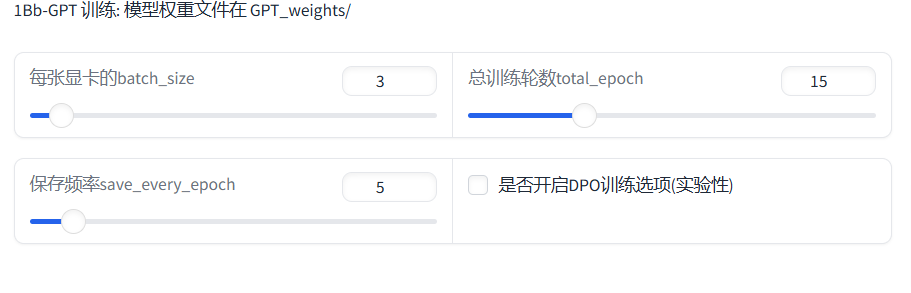
Step2.2设置
Step2.3 推理
待训练完成之后,就可以开始推理了。点击开启TTS推理webUI,能看到下面画面。在GPT和SoVITS模型列表,一般第一个就是你刚刚训练的模型,如果不是就换一下。
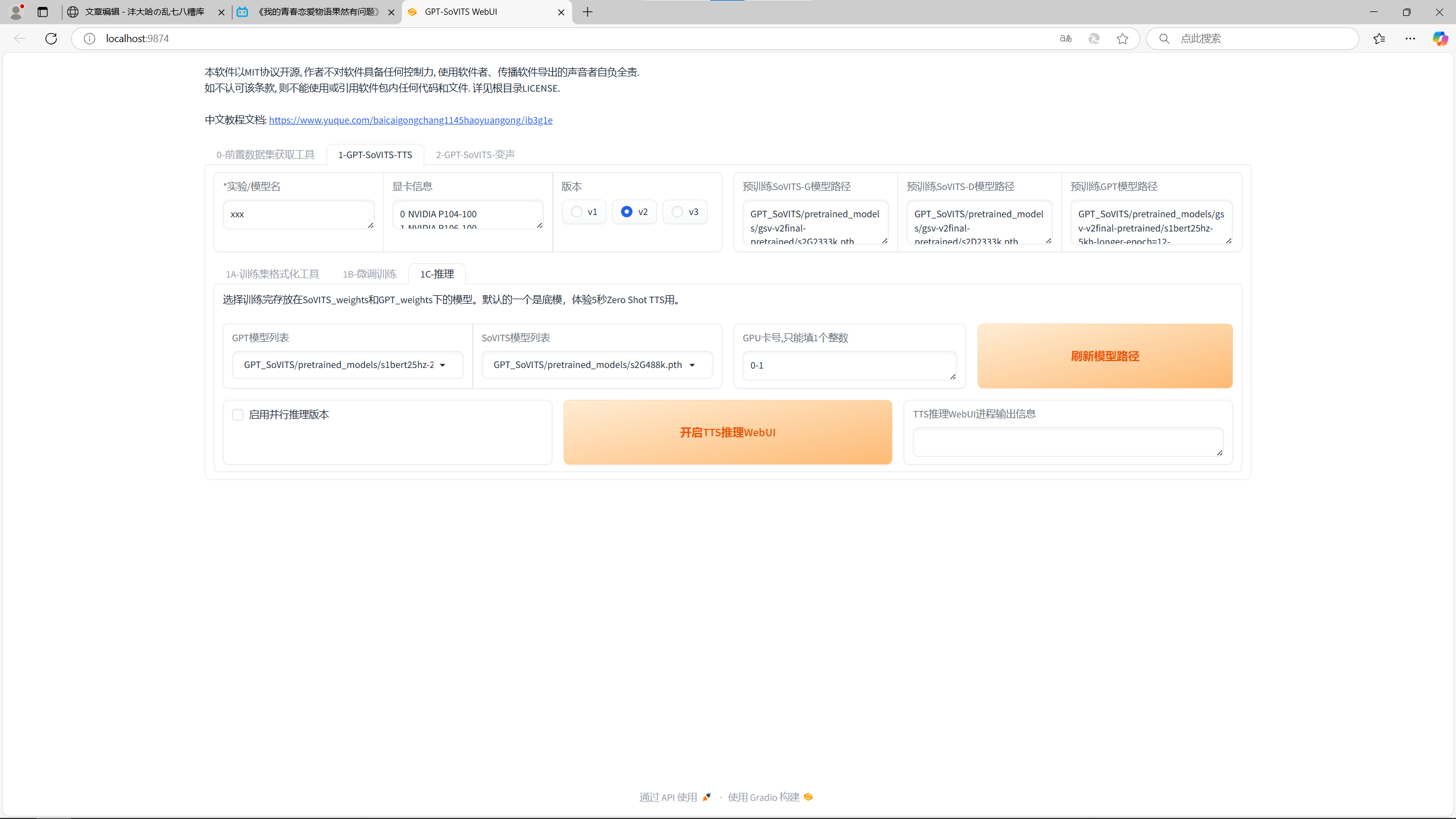
TTS推理webUI
进到页面之后可以看到你要上传一段参考信息,也就是一段音频,这个是必选的,与其对应的文字内容也可以输入进去。如果不输入文字内容的话,这个效果可能有点堪忧,和前面的语音降噪一样。如果你没有现成的素材也可以去另找一段音频,丢进第一步的人声分离webUI中,再用第三步的语音识别就可以得到音频和与之对应的文字内容了。当然在最右边你也可以上传多一点音频作为音色语调的参考内容,这个是可选的,而且不用输入文字内容。
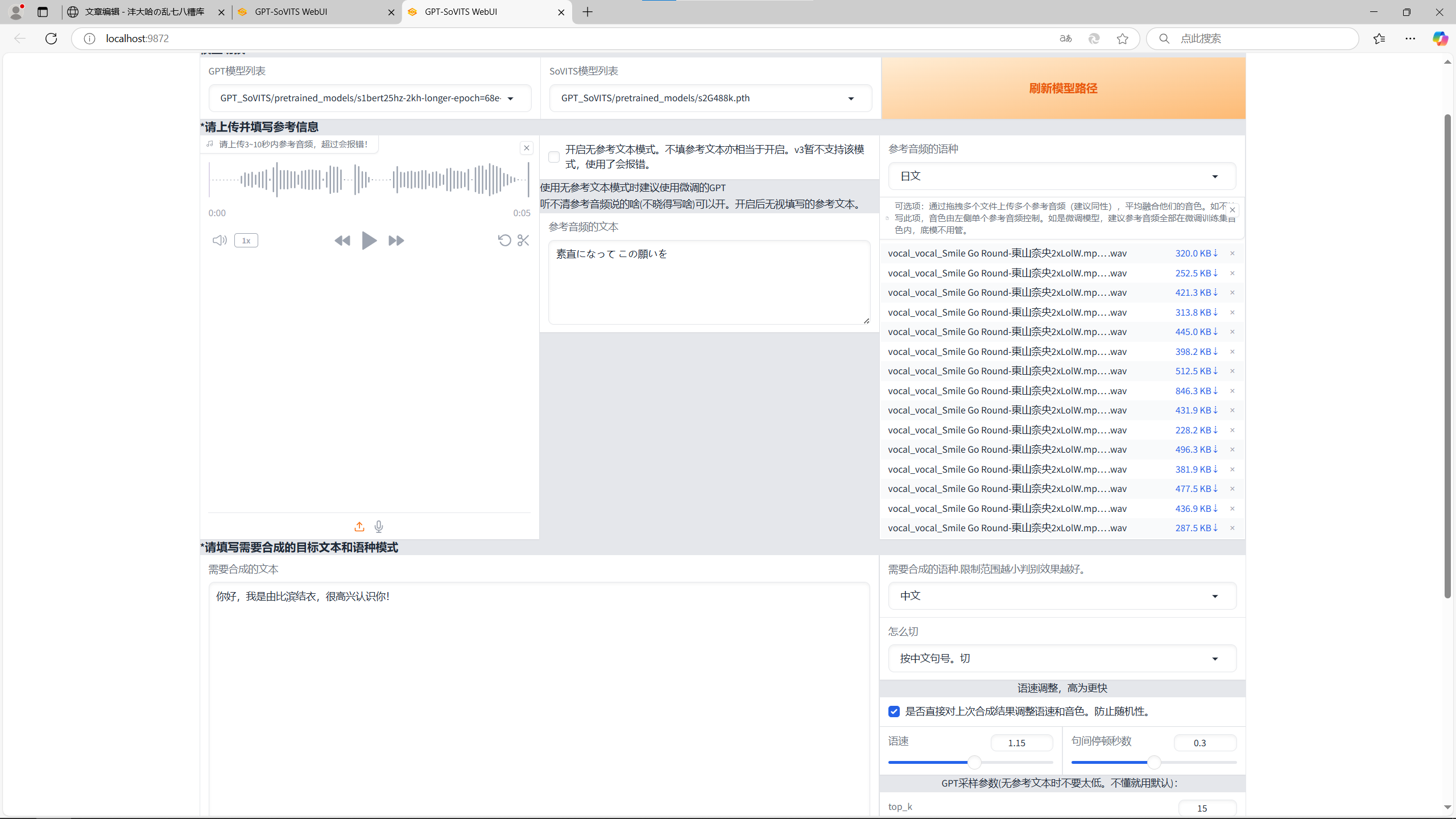
推理1
接着我们来看下面的内容,下面左边是你想要它生成的文字内容,往里输就行了。右边的话上面就是你要生成内容的语言,还有断句方式。这个断句方式其实就是方便显卡生成的,不断句一下子生成太多内容会爆显存,所以它会一段一段生成,再拼接起来。我个人认为就是生成中文按中文句号切是比较稳妥的,也没有什么违和感。语速和停顿时间按照自己的想法调就行了。
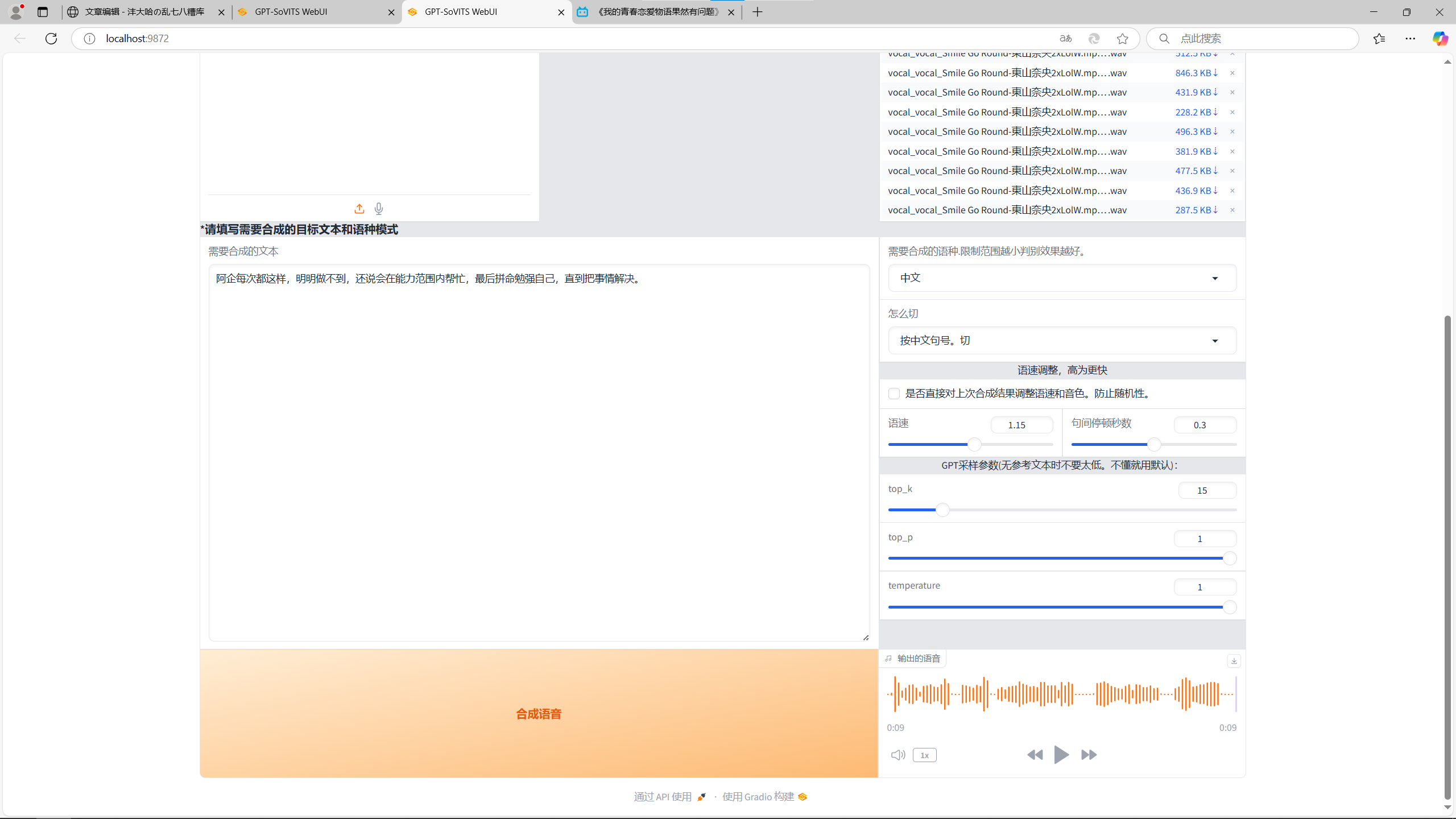
推理2
注意事项
1.不能关闭一开始打开的命令提示符!从中可以看见系统运行的日志和每个部分的进度!
2.显卡的显存必须要8G以上,否则在训练GPT模型时会爆显存,命令行中会显示错误!
3.在每次完成一个页面的任务的时候(如人声分离webUI),要记得关闭,因为它是会占用显存的!如果不关闭可能会影响之后的任务!
推理结果
我这里给大家放几段我训练的团子(春物中的由比滨结衣)的内容,用了一首四分钟的歌曲当作训练素材,P104-100和P106-100两张显卡一起训练出来的模型。感觉没有微调其实也很接近了,微调过后的效果肯定会更好。
1.幸好眼泪止住了,因为我哭的话,他就无法离开这里。我不会成为可怜的女孩,因为这样的话,他又会来救我,眼泪却到现在都停不住。
2.你好,我是由比滨结衣,很高兴认识你!
3.阿企每次都这样,明明做不到,还说会在能力范围内帮忙,最后拼命勉强自己,直到把事情解决。
4.很多事情你不说,别人是不明白的。——你也没说出口,满口都是粉饰后的话语。
总结
这次的模型还是很好玩的,能够用人声来配音,门槛还是有的,但是并不高,大概一个晚上三四个小时就能搞定,主要还是训练的时间比较长,看每个人的显卡不同吧。现在一般大学生笔记本应该都是8G的4060显卡,所以可能运行不太了。如果有台式机的话,可以买两张便宜的矿卡,向我这次用的P106-100和P104-100,两张总价也就是一次乐子的钱,所以说很经济实惠。
世上无难事,只要肯折腾。祝你好运!